Custom Code Example: Duplicate Document Check¶
Overview¶
This guide walks you through implementing a robust duplicate-document prevention pattern in AIForged using:
- A Custom Code utility service (as a post-processor)
- A Custom Dataset (“Duplicate History”)
- Work item creation for Human-in-the-Loop (HITL) review when duplicates are detected
At a high level:
- Each incoming document’s bytes are hashed (MD5 by default).
- The hash is looked up in a Custom Dataset.
- If a match exists, the document is flagged as Error, skipped from downstream processing, and a HITL work item is created.
- If no match is found, the hash is recorded and the document continues.
Info
Note: MD5 is adequate for duplicate detection in most business contexts. For stronger collision resistance, see the “Extensions” section to switch to SHA‑256.
Architecture at a Glance¶
- Trigger: Email Scraper’s nested Attachment service processes new attachments as documents.
- Post-processor: Custom Code utility runs after the attachment service has scraped attachments from an email (recommended placement).
- Storage: “Duplicate History” Custom Dataset stores (MD5Hash, DocumentId).
- Decision:
- If MD5 exists in dataset → set DocumentStatus=Error, create WorkItem for verification, skip further processing.
- Else → store MD5 and allow the document to proceed.
Prerequisites¶
- An existing Email Scraping service with the nested Attachment service.
- Permission to add utility services and create custom datasets.
- .NET cryptography assembly access to compute hashes.
Step 1 — Add the Custom Code Utility¶
- Open the Service Flow Configurator for the Email Scraping service by clicking on the Open Service Flow Configurator
 button.
button.
- Expand the Utilities service group.
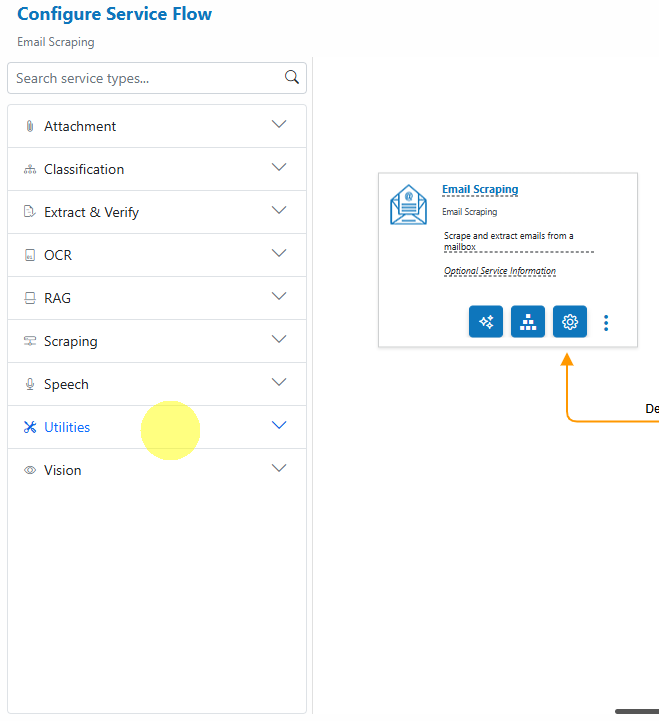
- Drag the Custom Code service type card over the Attachment Service card, then to the Post-Processor drop point.
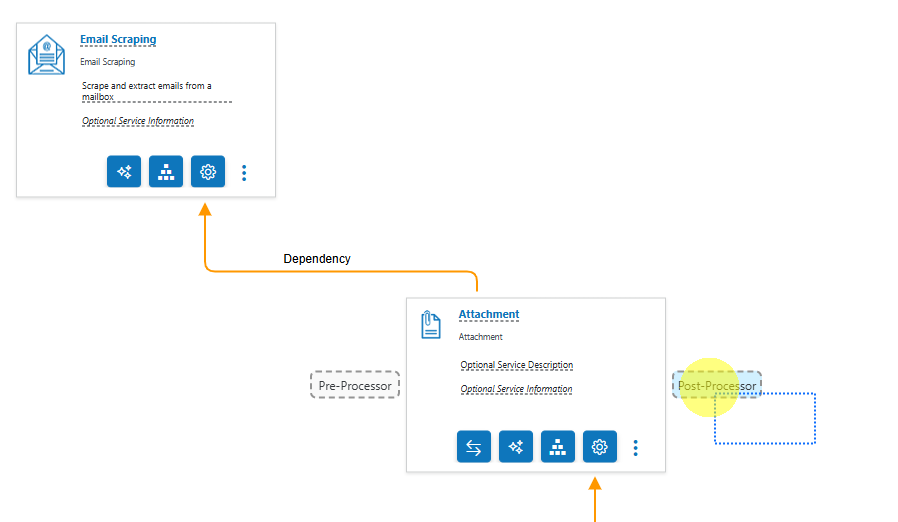
- Save.
Info
Recommendation: Position this Custom Code utility as a post-processor (execute after the parent) to prevent duplicates from flowing into downstream steps.
Step 2 — Create the “Duplicate History” Custom Dataset¶
- Open the Parameter Definitions dialog of the new Custom Code utility service.
- Click on the Create Custom Dataset
 button.
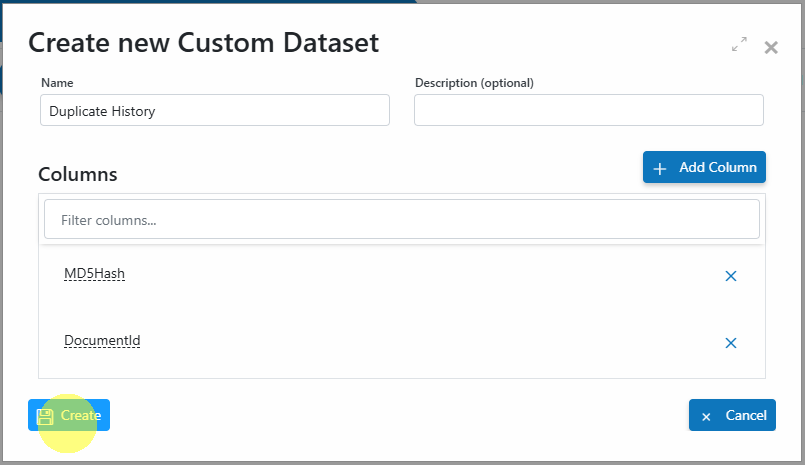
button. - Enter Duplicate History in the Name field and add the following two columns:
- MD5Hash (ValueType: String)
- DocumentId (ValueType: String)
- Click Create to persist the dataset schema.
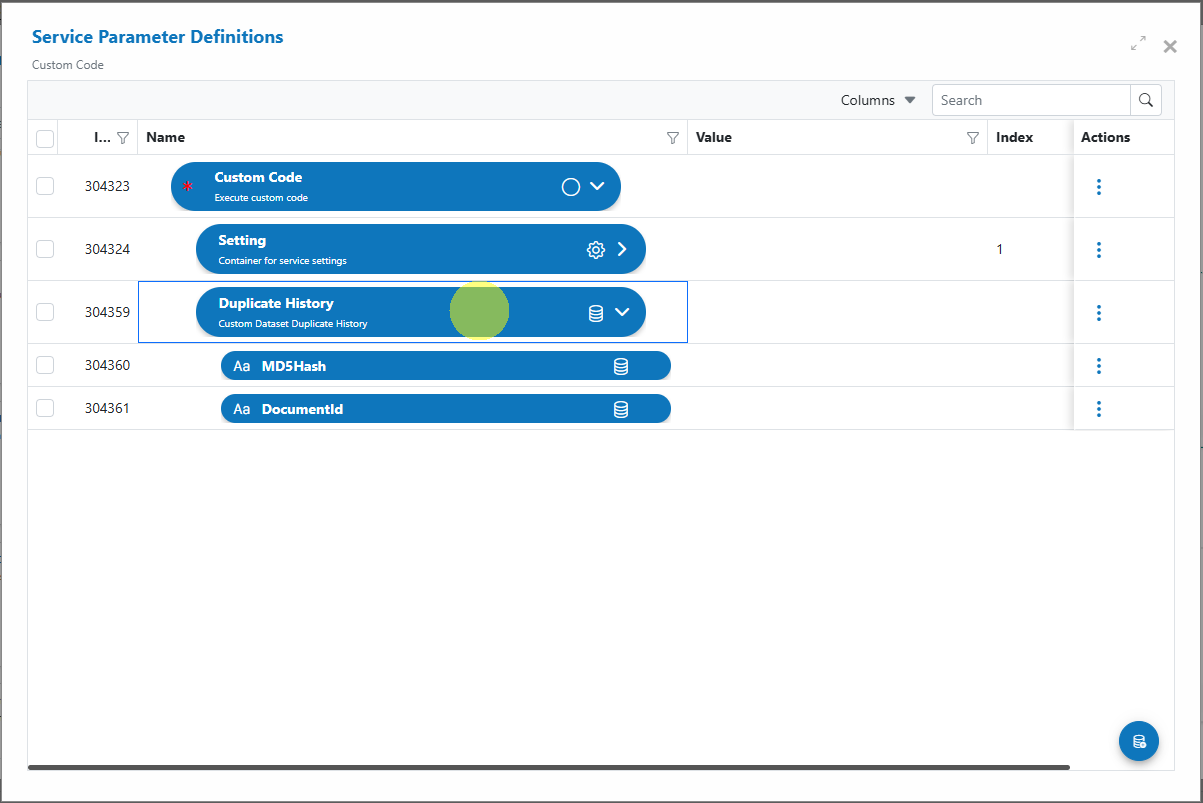
Your dataset should now appear in the Service Parameter Definitions dialog:\
Step 3 — Add the Custom Code¶
-
Close the Service Parameter Definitions dialog and click the Code button on the nested Custom Code service card.
-
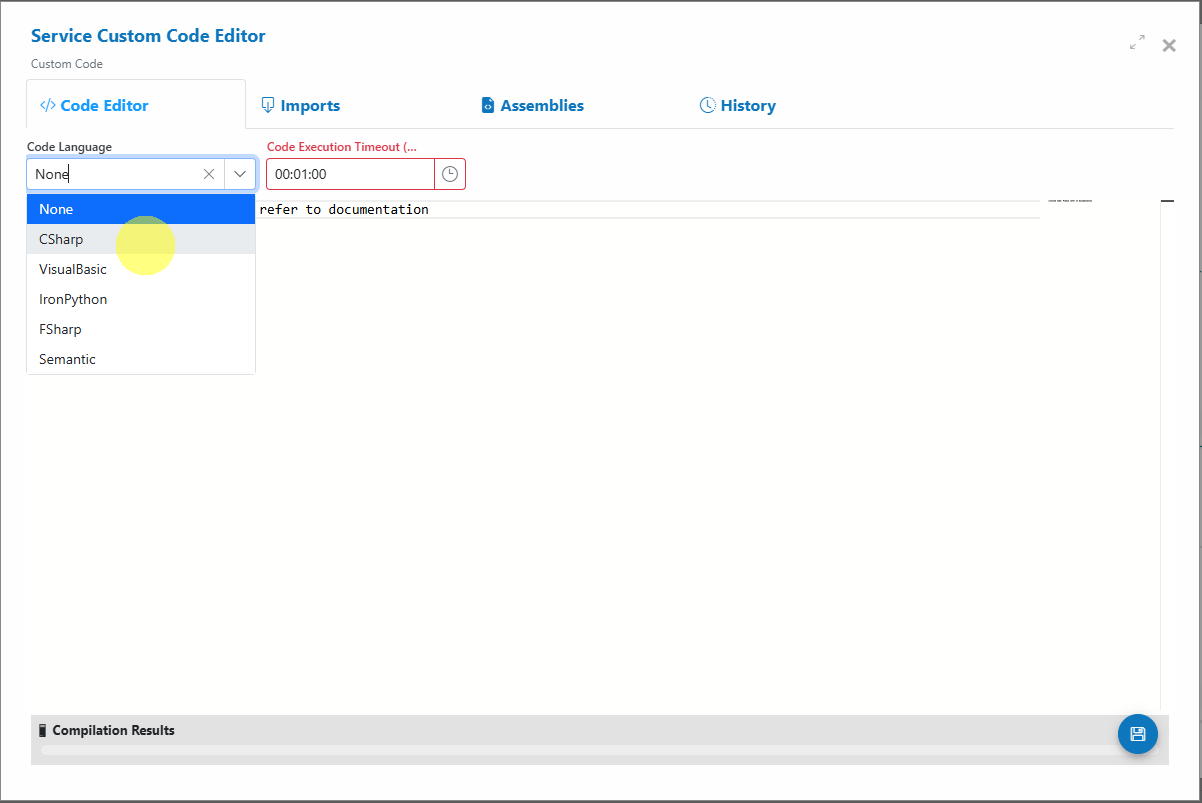
Select CSharp as Code Language.
-
Paste the reference implementation below into the editor.
Reference Implementation¶
// Log the start
logger.LogInformation("{stpd} Start", stpd.Name);
// 0) Exit if there are no documents
if (docs == null || !docs.Any())
{
logger.LogInformation("{stpd} Found no docs, continuing...", stpd.Name);
return new AIForged.Services.ProcessResult(docs);
}
// 1) Identify the parent (Attachment) service
var parentservice = module.GetParentService();
logger.LogInformation("{stpd} Found {count} docs...", stpd.Name, docs.Count());
// 2) Retrieve the Duplicate History dataset (replace IDs with your own)
logger.LogInformation("{stpd} Get Custom History DataSet", stpd.Name);
// REQUIRED: update these IDs to match your dataset and fields
const int DuplicateHistoryDataSetDefId = 1234;
const int FieldDocIdDefId = 1235;
const int FieldMD5HashDefId = 1236;
// OPTIONAL: group used for HITL assignment (replace with your groupId)
const int GroupId = 123123;
// Load dataset and resolve fields
ICustomDataSet dataset = module.GetDataSetByDef(stpd, DuplicateHistoryDataSetDefId, false, false, null, null, null, null);
if (dataset == null)
{
logger.LogInformation("{stpd} Unable to load Duplicate History dataset (defId={defId})", stpd.Name, DuplicateHistoryDataSetDefId);
return new AIForged.Services.ProcessResult(docs);
}
ParameterDefViewModel fieldDocId = dataset.FindField(FieldDocIdDefId);
ParameterDefViewModel fieldMD5Hash = dataset.FindField(FieldMD5HashDefId);
if (fieldDocId == null || fieldMD5Hash == null)
{
logger.LogInformation("{stpd} Dataset fields not found (docIdDefId={docIdDefId}, md5DefId={md5DefId})", stpd.Name, FieldDocIdDefId, FieldMD5HashDefId);
return new AIForged.Services.ProcessResult(docs);
}
// 3) Identify verification users (optional, for work item assignment)
var verifyusers = module.GetUsers(
parentservice.Id,
GroupId,
new[] { GroupRoleType.VerifyDoc },
null
);
// Track documents to skip from downstream processing
List<int> skippedDocIds = new List<int>();
// 4) Process each child document
foreach (IDocument childDoc in docs.ToList())
{
try
{
// 4.1) If already in error, create a work item and skip
if (childDoc.Status == DocumentStatus.Error)
{
logger.LogInformation("{stpd} Document is in error state: {docid}", stpd.Name, childDoc.Id);
var usr = verifyusers?.Select(t => t.user).Distinct().ToList();
var picked = (usr == null || usr.Count == 0) ? null : module.PickRandom(usr, null);
if (picked != null)
{
var wi = module.CreateWorkItem(
picked.UserId,
WorkItemType.Document,
WorkItemStatus.Created,
WorkItemAction.Verify,
WorkItemMethod.Random,
new TimeSpan(24, 0, 0),
parentservice.Id,
childDoc.MasterId,
null, null, null, null, null,
GroupId,
childDoc.Comment,
childDoc.Result,
null, null, null, null,
null, null
);
module.SaveChanges();
}
skippedDocIds.Add(childDoc.MasterId ?? childDoc.Id);
continue;
}
// 4.2) Load document data for hashing
logger.LogInformation("{stpd} Process Document {docid} {docfilename}", stpd.Name, childDoc.Id, childDoc.Filename);
logger.LogInformation("{stpd} Get document data", stpd.Name);
// Prefer the original Image bytes, fallback to first available blob
var blobs = module.GetDocumentData(childDoc, new List<DocumentDataType?> { DocumentDataType.Image })
?? module.GetDocumentData(childDoc, null);
var primary = blobs?.FirstOrDefault(b => b.Type == DocumentDataType.Image) ?? blobs?.FirstOrDefault();
var bytes = primary?.Data;
if (bytes == null || bytes.Length == 0)
{
logger.LogInformation("{stpd} Could not get document data for hashing", stpd.Name);
module.SetDocumentStatus(childDoc, DocumentStatus.Error, "Could not get document data to calculate MD5 hash.", null, true, false, true);
skippedDocIds.Add(childDoc.MasterId ?? childDoc.Id);
module.SaveChanges();
continue;
}
// 4.3) Compute MD5
logger.LogInformation("{stpd} Compute document MD5 hash", stpd.Name);
string hashString;
using (var md5 = System.Security.Cryptography.MD5.Create())
{
var hashBytes = md5.ComputeHash(bytes);
hashString = BitConverter.ToString(hashBytes).Replace("-", "");
}
if (string.IsNullOrWhiteSpace(hashString))
{
logger.LogInformation("{stpd} Could not calculate document's MD5 hash", stpd.Name);
module.SetDocumentStatus(childDoc, DocumentStatus.Error, "Could not calculate document's MD5 hash", null, true, false, true);
skippedDocIds.Add(childDoc.MasterId ?? childDoc.Id);
module.SaveChanges();
continue;
}
// 4.4) Check for duplicates
var matches = module.GetDataSetRecords(dataset, fieldMD5Hash, hashString, false);
if (matches != null && matches.Any())
{
// Duplicate found
var first = matches.FirstOrDefault();
var priorId = first?.GetValue(fieldDocId)?.Value ?? "Unknown";
logger.LogInformation("{stpd} Duplicate detected. Prior: {prior}", stpd.Name, priorId);
module.SetDocumentStatus(childDoc, DocumentStatus.Error, $"Document already processed: Previous document info: {priorId}", null, true, false, true);
var usrPool = verifyusers?.Select(t => t.user).Distinct().ToList();
var picked = (usrPool == null || usrPool.Count == 0) ? null : module.PickRandom(usrPool, null);
if (picked != null)
{
var wi = module.CreateWorkItem(
picked.UserId,
WorkItemType.Document,
WorkItemStatus.Created,
WorkItemAction.Verify,
WorkItemMethod.Random,
new TimeSpan(24, 0, 0),
parentservice.Id,
childDoc.MasterId,
null, null, null, null, null,
GroupId,
childDoc.Comment,
childDoc.Result,
null, null, null, null,
$"Document already processed: Previous document info: {priorId}",
$"Document already processed: Previous document info: {priorId}"
);
module.SaveChanges();
}
skippedDocIds.Add(childDoc.MasterId ?? childDoc.Id);
continue;
}
// 4.5) No duplicate found → store hash and proceed
logger.LogInformation("{stpd} New document. Create dataset record.", stpd.Name);
var newRecord = dataset.CreateRecord(Guid.NewGuid().ToString());
newRecord.SetValue(fieldDocId.Id, $"Parent Doc Id: {childDoc.MasterId?.ToString() ?? "N/A"} | Doc Id: {childDoc.Id}");
newRecord.SetValue(fieldMD5Hash.Id, hashString);
await module.SaveDataSetRecord(dataset, newRecord);
module.SaveChanges();
logger.LogInformation("{stpd} Hash record created. Continuing...", stpd.Name);
// Place for additional post-processing, if needed
// ...
}
catch (Exception ex)
{
logger.LogInformation("{stpd} Error while processing doc {docid}: {ex}", stpd.Name, childDoc.Id, ex.ToString());
// Consider: set to Error and create a work item here as well
}
}
// 5) Remove skipped docs from downstream processing
foreach (var skippedId in skippedDocIds.Distinct())
{
var skipped = docs.FirstOrDefault(d => d.Id == skippedId);
if (skipped != null) docs.Remove(skipped);
}
// 6) Return the remaining documents to continue the pipeline
return new AIForged.Services.ProcessResult(docs);
Step 4 — Replace IDs with Your Own¶
Where indicated in the code:
- DuplicateHistoryDataSetDefId → Your Duplicate History dataset definition ID
- FieldMD5HashDefId → Your MD5Hash field definition ID
- FieldDocIdDefId → Your DocumentId field definition ID
- GroupId → Your group for verification user assignment
Info
For stability, consider reading these IDs from service settings (Parameter Definitions with Category=Setting) or use Constants instead of hard-coding.
Step 5 — Add Required Assembly¶
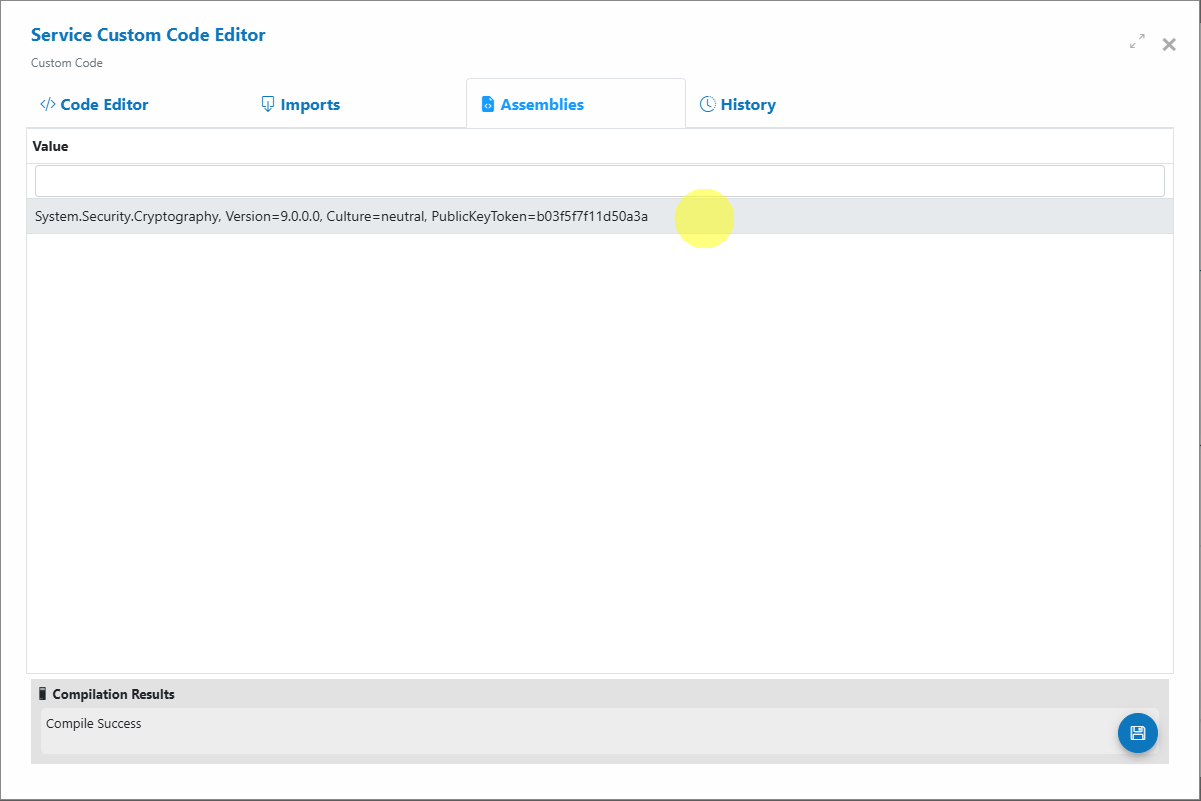
To compute MD5, add this assembly to the Custom Code “Assemblies” list:
System.Security.Cryptography, Version=9.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
Step 6 — Add Required Import¶
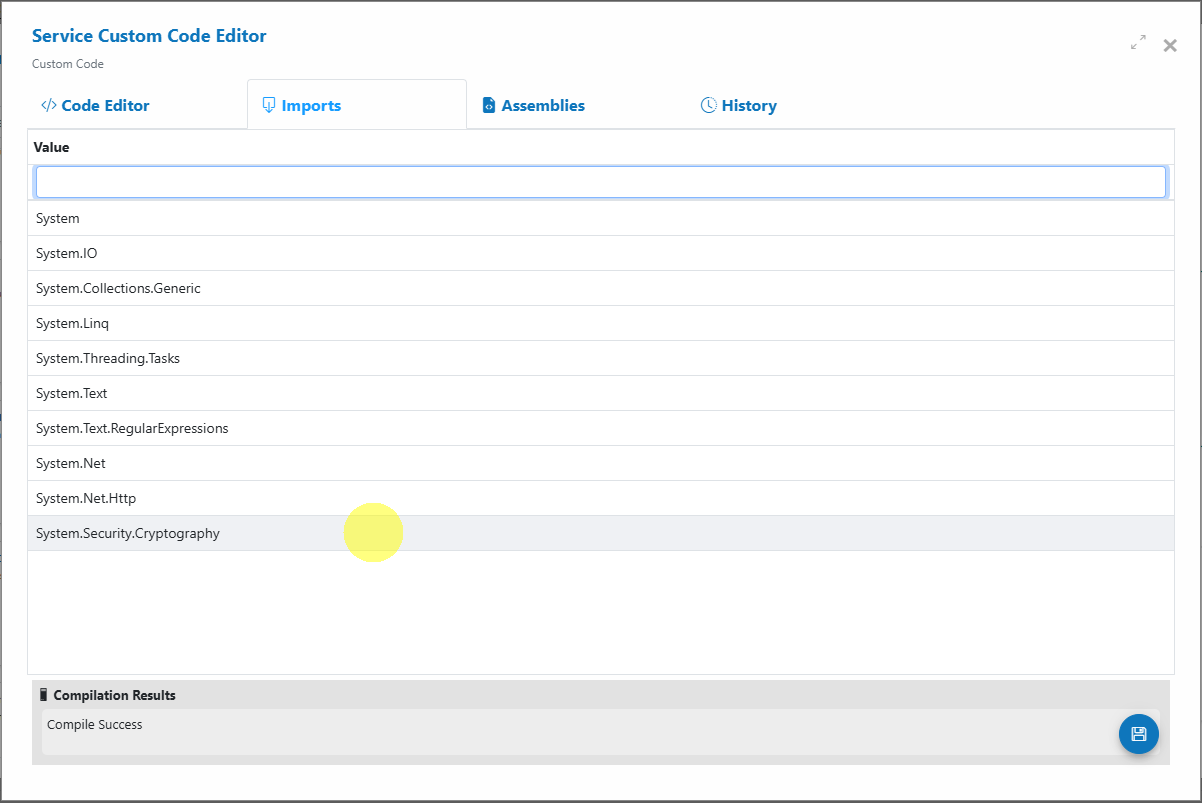
To compute MD5, add this import to the Custom Code “Imports” list:
System.Security.Cryptography
Step 7 — Save Your Code¶
Click the Save  button or use the key combination Ctrl+S regularly to persist changes.
button or use the key combination Ctrl+S regularly to persist changes.
Step 8 — Test the Solution¶
- Send two identical documents as attachments to the mailbox your Email Scraper monitors.
- On the first run:
- The Custom Code utility computes the MD5, finds no match, stores it, and lets processing continue.
- On the second run (duplicate):
- The utility computes the same MD5, finds a match in the dataset, sets the document to Error, creates a HITL work item, and excludes the doc from downstream processing.
- Verify:
- A record exists in the Duplicate History dataset for the first doc’s hash.
- The duplicate document has DocumentStatus=Error.
- A WorkItem exists for HITL verification (assignee from your verification group).
Operational Guidance¶
- Placement: Run this utility before heavy extractors to save cost/time.
- Logging: Keep info-level logs for visibility; add debug logs during pilots.
- Concurrency: Setting MD5Hash as dataset Key and handling duplicate insert failures will harden against race conditions.
- Performance: Hashing is CPU-bound; keep batch sizes reasonable. For very large files, consider streaming hashes.
- Retention: Decide how long to keep hashes. Add an archiving policy to trim old entries if needed.
Troubleshooting¶
- No users for assignment
- Ensure your GroupId is correct and that VerifyDoc users are active/enabled.
- “Could not get document data”
- Confirm the document has a valid Image blob. Check upstream services that provide the original bytes.
- Repeated duplicates not flagged
- Verify that FieldMD5HashDefId points to the correct field and that lookups aren’t case-sensitive in your dataset. Confirm the hash string matches exactly.
- Too many false positives
- Extremely rare with MD5 for identical bytes. If source documents differ by metadata but represent “the same” logical document, consider normalizing (e.g., PDF linearization) or hashing page images.
- Performance concerns
- Stream hashing on very large files, reduce batch size, and tune service BatchSize. Monitor CPU.
Extensions (Optional)¶
-
Use SHA‑256 instead of MD5 Replace MD5 with SHA256 for stronger collision resistance:
using var sha = System.Security.Cryptography.SHA256.Create(); var hashBytes = sha.ComputeHash(bytes); var hashString = BitConverter.ToString(hashBytes).Replace("-", ""); -
Make MD5Hash the dataset Key Enforce uniqueness at the dataset level to prevent duplicate inserts.
- Broaden matching logic Include additional heuristics (e.g., page count + file size) for pre-filtering before hashing large files.
- Custom work item routing Swap WorkItemMethod.Random for Idle or HighThroughput, or route to ProjectOwner/DocumentOwner depending on your workflow.