Google OCR¶
Overview¶
The Google OCR Service in AIForged uses Google Cloud’s OCR capabilities to extract plain text from documents. It returns raw text without preserving layout or structure and stores the output in the document’s Result property for downstream processing, analysis, or integration.
Info
Use this service when you need reliable plain text extraction for workflows such as data mining, regex pattern detection, search indexing, or downstream AI processing.
Supported Content Types¶
- JPEG
- PNG
- TIFF
Info
If your content is in a different format, use the AIForged PDF Converter to generate a compatible file.
Possible Use Cases¶
- Extract text from scans of receipts, invoices, contracts, letters, and forms.
- Run RegEx patterns on extracted text to detect and structure key information.
- Index documents for search and retrieval.
- Prepare datasets for machine learning and analytics.
Service Setup¶
Follow these steps to add and configure the Google OCR Service to your agent:
- Open the Agent View: Navigate to the agent where you want to add the service.
- Add the Google OCR Service:
Click the Add Service
 button.
button. - Select Service Type:
Choose Google OCR Service from the available service types.
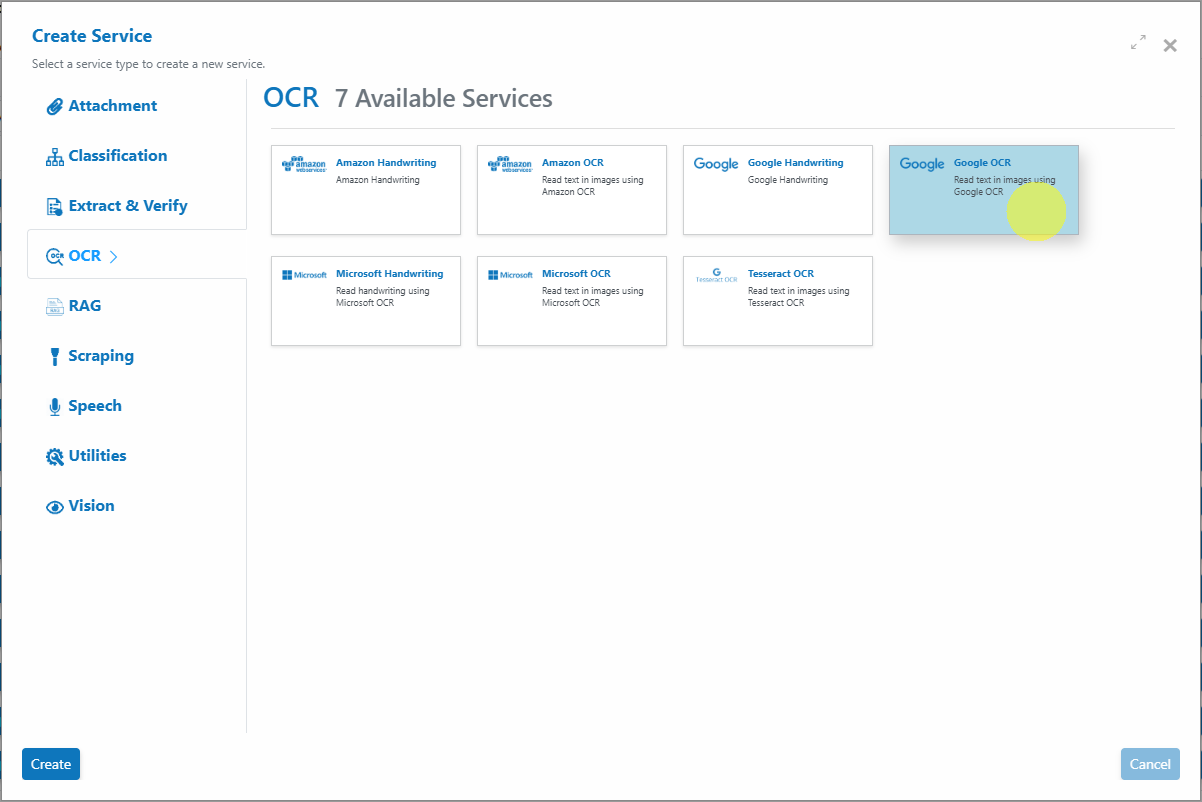
-
Configure the Service Wizard:
- Open the Service Configuration Wizard.
- Or
-
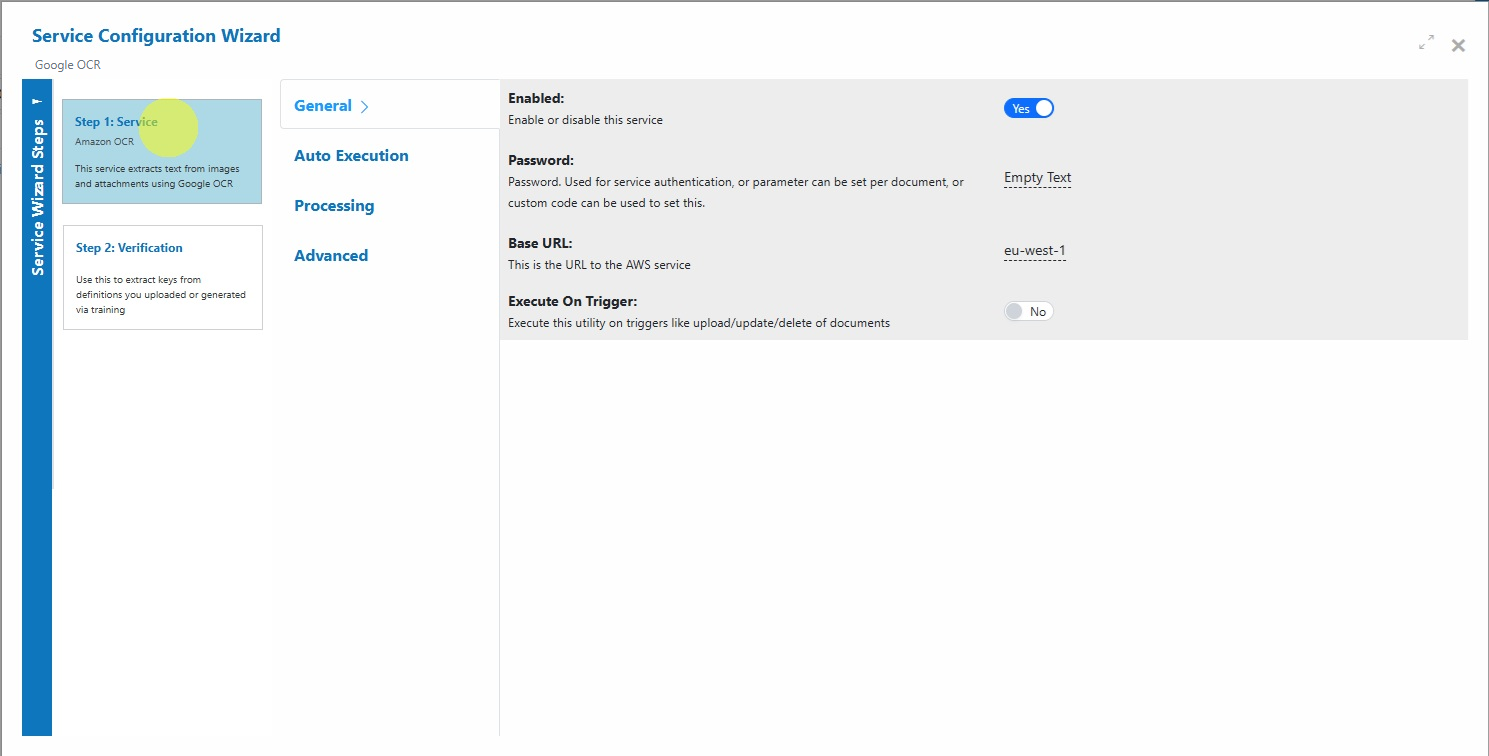
Step 1: General Settings: Configure core settings such as service name and description. Default settings are sufficient for most use cases.
-
Step 2: Verification: No verification is typically required for plain text OCR unless paired with downstream validation.
Service Configuration Settings¶
Most users can proceed with the default settings. Advanced configuration is available for custom workflows.
| Setting | Type | Required? | Description |
|---|---|---|---|
| ArchivingStrategy | Optional | No | Number of days before documents are archived or deleted. |
| AccessKey | Optional | No | Override the Google Cloud credentials/API key configured for this service (typically not required). |
| BaseURL | Optional | No | Override the Google Cloud OCR endpoint (advanced; usually not required). |
| BatchSize | Hidden | - | Processing batch size. |
| CheckElectronic | Optional | No | If the document is electronic, extract text directly where possible. |
| DocumentProcessedStatus | Optional | No | Document status applied after successful processing. |
| Enabled | Hidden | - | Enable or disable the service. |
| ExecuteBeforeProcess | Optional | No | If configured as a child service, execute before the parent service. |
| ExecuteAfterProcess | Optional | No | If configured as a child service, execute after the parent service. |
| IsVerification | Optional | No | Save OCR results (lines/words) for human verification. |
| Language | Optional | No | Provide a language hint to improve recognition accuracy. |
| MinSize | Optional | No | Minimum document size threshold to trigger OCR. |
| Password | Optional | No | Authentication password; can be set per document via custom code. |
| RemoveComments | Optional | No | Remove human comments/annotations before processing. |
Info
If unsure, keep defaults unless you have a specific processing or integration requirement.
Add and Process Documents¶
To upload and process documents using the Google OCR Service:
- Open Service: When you open the Google OCR Service, you will be presented with the documents currently queued or processed in the Inbox.
- Upload Documents:
Click the Upload
 button or drag and drop files over the document grid.
button or drag and drop files over the document grid.
- Select Category (Optional): If you know the category for the document, select it. Otherwise, select No category.
- Process Documents:
After uploading, select the documents to process and click Process Checked.

Info
Tip: For new services, process a small batch first to verify OCR accuracy before scaling up.
View Processed Documents¶
-
Use the usage filter to select Outbox in the Google OCR Service.
-
Open any processed document to view the extracted text in the Result property.
Troubleshooting Tips¶
- Text Missing or Incorrect?
- Verify document quality and resolution (aim for 300 DPI).
- Set the Language hint for non-English documents.
- Ensure the file type is supported (PDF, JPEG, PNG, TIFF).
- Unexpected Characters or Symbols?
- Complex fonts, handwriting, or artifacts can affect OCR.
- Pre-process images (contrast, brightness, noise reduction) before uploading.
- Slow Performance?
- Large documents or batches may take longer—process smaller sets where possible.
- Check BatchSize if configured unusually high.
- Upload or Processing Errors?
- Re-upload a clean version of the file to rule out corruption.
- Convert to PDF using the AIForged PDF Converter if issues persist with image formats.
- Review service settings or contact support if errors continue.
Best Practices¶
- Use high-quality scans (300 DPI recommended) or digital originals for optimal OCR accuracy.
- Provide a language hint in settings when processing documents that are not in English.
- Avoid password-protected PDFs unless you supply the password in the configuration.
- Pre-process poor-quality images (deskew, denoise, increase contrast) to improve results.
- Keep file sizes reasonable; extremely large images may slow processing without quality benefits.
Known Limitations¶
The following provider constraints apply to Amazon Textract-backed OCR:
- Supported formats
- JPEG, PNG, PDF, and TIFF. XFA-based PDFs are not supported.
- Size and page limits
- Synchronous operations: up to 10 MB in memory; PDF/TIFF limited to 1 page.
- Asynchronous operations: PDF/TIFF up to 500 MB and up to 3,000 pages.
- PDF specifics
- PDFs cannot be password protected.
- Use the AIForged Custom Code utility as a pre-processor to set the password per document, so that AIForged can unlock documents before processing.
- Max page size: up to 40 inches (2880 points).
- JPEG 2000 images embedded in PDFs are supported.
- PDFs cannot be password protected.
- Image constraints
- Max resolution supported is 10,000 pixels on any side.
- Minimum detectable character height is ~15 pixels (approx. 8 pt at 150 DPI).
- All in-plane rotations are supported.
- Language and script
- Printed text detection supports multiple Latin-based languages.
- Handwriting recognition is supported for English only.
- Vertical text layouts (e.g., vertical East Asian scripts) are not supported.
- Language is not returned in the output for standard text detection.
- Query features (if used)
- Per-page limits apply (e.g., max queries per page in sync/async modes).
Info
Tip: For very large PDFs or TIFFs, consider chunking by page range to avoid hitting page or size limits and to keep processing responsive. Use the AIForged Document Splitter for this task.
Permissions Required¶
Members must belong to one of the following AIForged user group roles to add and configure this service:
- Owner
- Administrator
- Developer
Info
Tip: Role membership is managed in Organisations > Roles. Assign members to roles to grant agent and service administration access.