☁️ OneDrive Scraper¶
Overview¶
The OneDrive Scraper connects to a specified OneDrive folder via Microsoft Graph and imports new or updated files into your agent on a schedule. This enables a secure “drop folder” intake pattern for documents that automatically flow into downstream Services (OCR, Document Intelligence, rules, exports, and more).
Info
Use OneDrive Scraper to create a hands-off intake pipeline: team members (or partners) drop files into a shared OneDrive folder, and AIForged ingests them for processing.
Permissions required¶
Members must belong to one of the following AIForged roles to add and configure this Service: - Owner - Administrator - Developer
Tip
Manage role membership in Organizations → Roles. Assign members to grant agent and Service administration access.
Supported content types¶
The OneDrive Scraper can ingest most common file types stored in OneDrive, including:
- Images (JPEG, PNG, TIFF)
- Office documents (Word, Excel, PowerPoint)
- Text files
Info
If your content is in a different format, use the AIForged PDF Converter downstream to normalize inputs for processing.
Possible use cases¶
- “Drop folder” intake for invoices, statements, or forms shared by internal teams or suppliers.
- Batch ingestion of scans exported from MFPs or mobile capture apps into a monitored OneDrive folder.
- Departmental pipelines (AP, HR, Legal) that require secure, auditable intake with minimal user interaction.
Service setup¶
Follow these steps to add and configure the OneDrive Scraper in your agent:
-
Open the Agent view
Navigate to the agent where you want to add the Service. -
Add the OneDrive Scraper
Click Add Service button and choose OneDrive Scraper.
button and choose OneDrive Scraper.
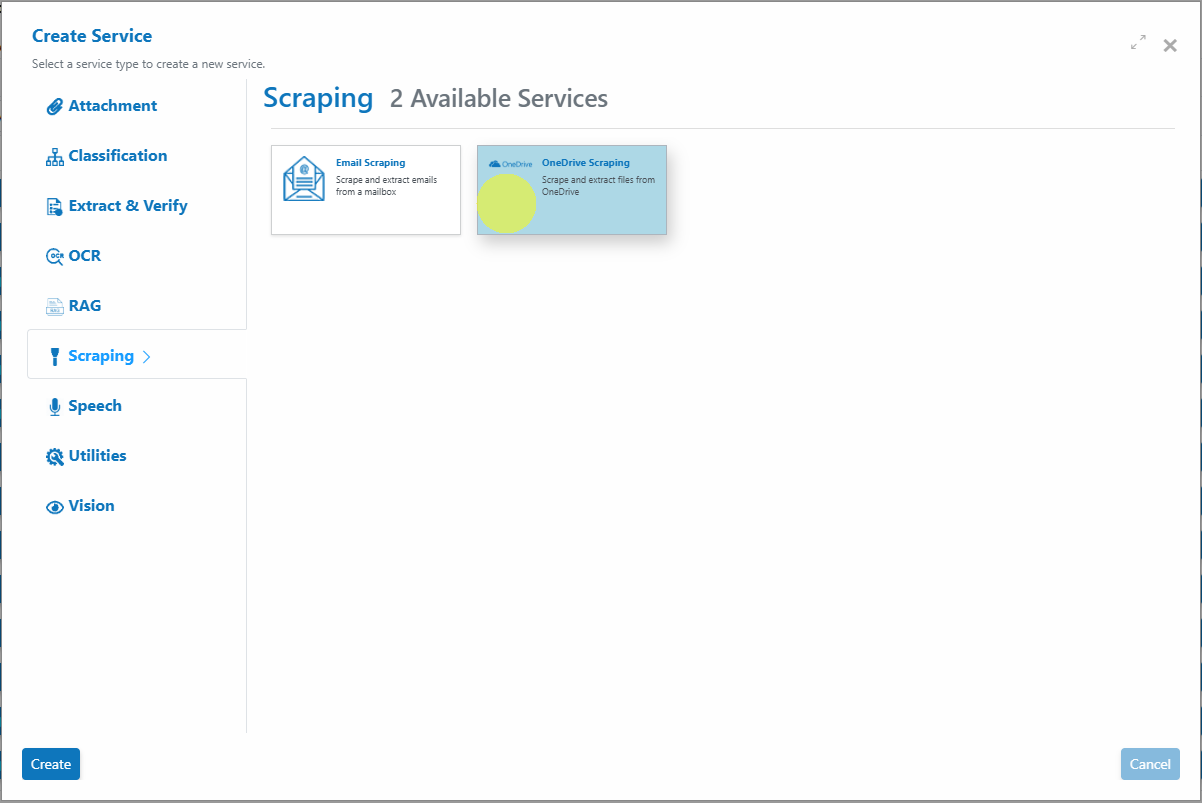
-
Configure the Service Wizard
The wizard includes:
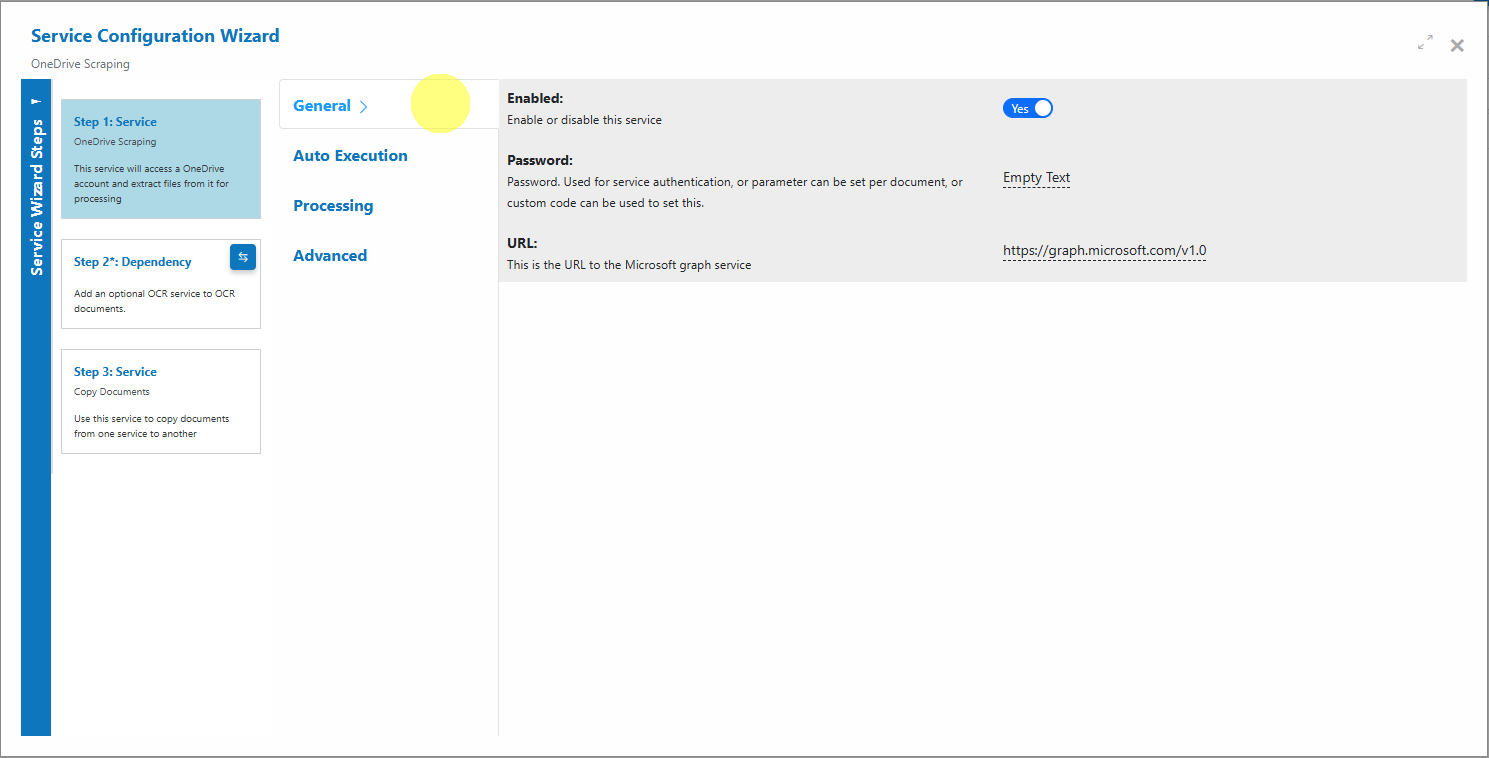
General
Enable the Service and provide any required authentication parameters.
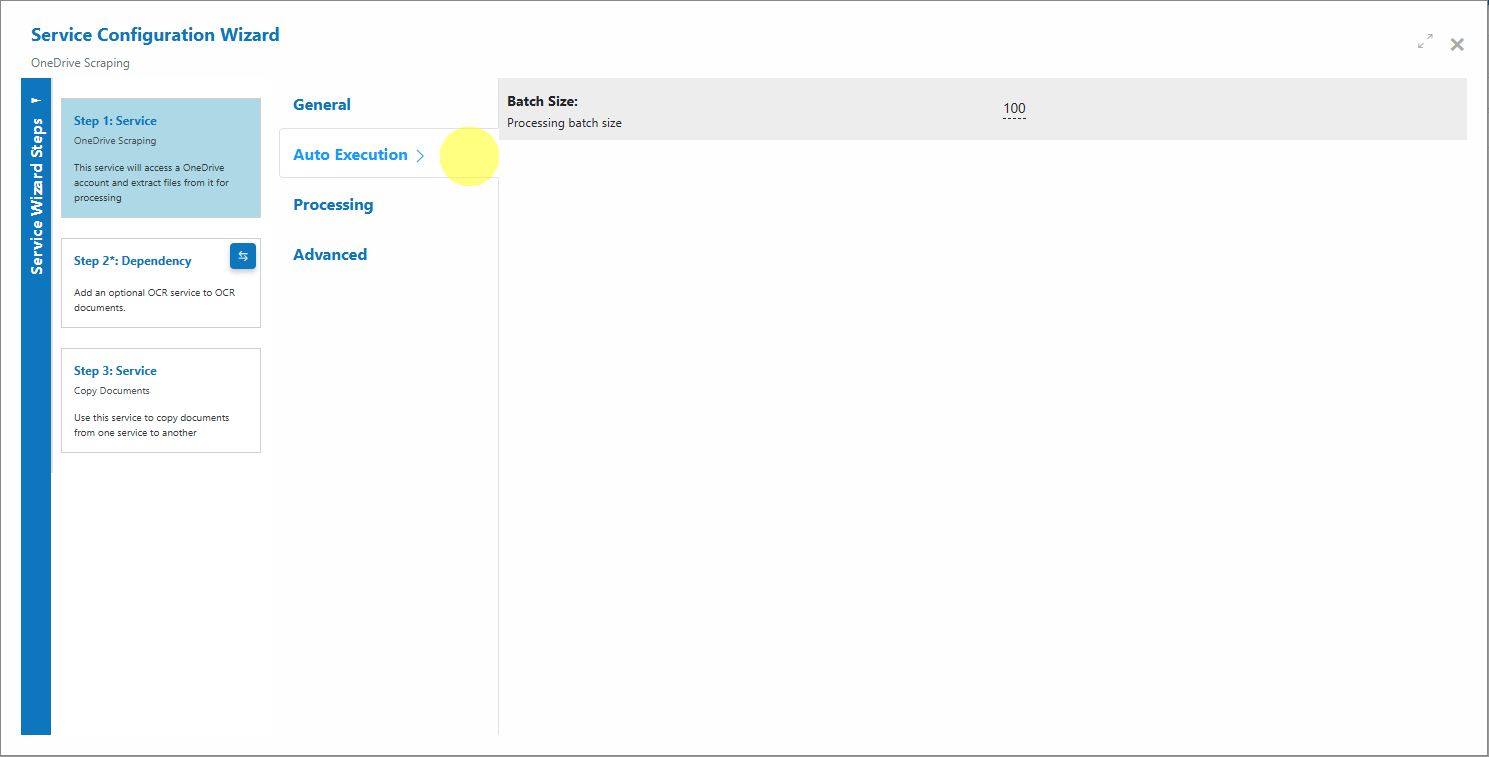
Auto Execution
Set the automatic run schedule and Batch Size (how many items are pulled per cycle).
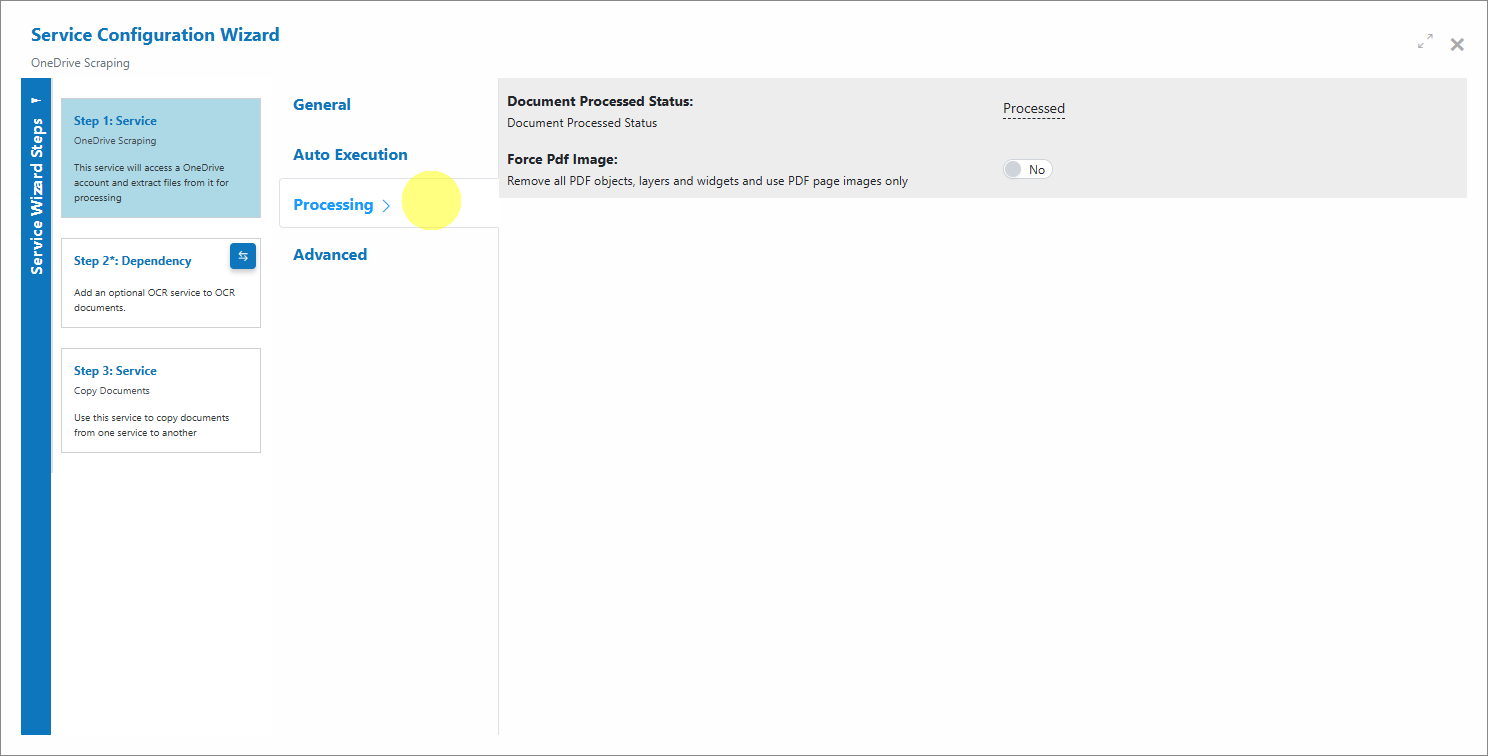
Processing
Choose the Document Processed Status and whether to force PDFs to image-only for downstream OCR.
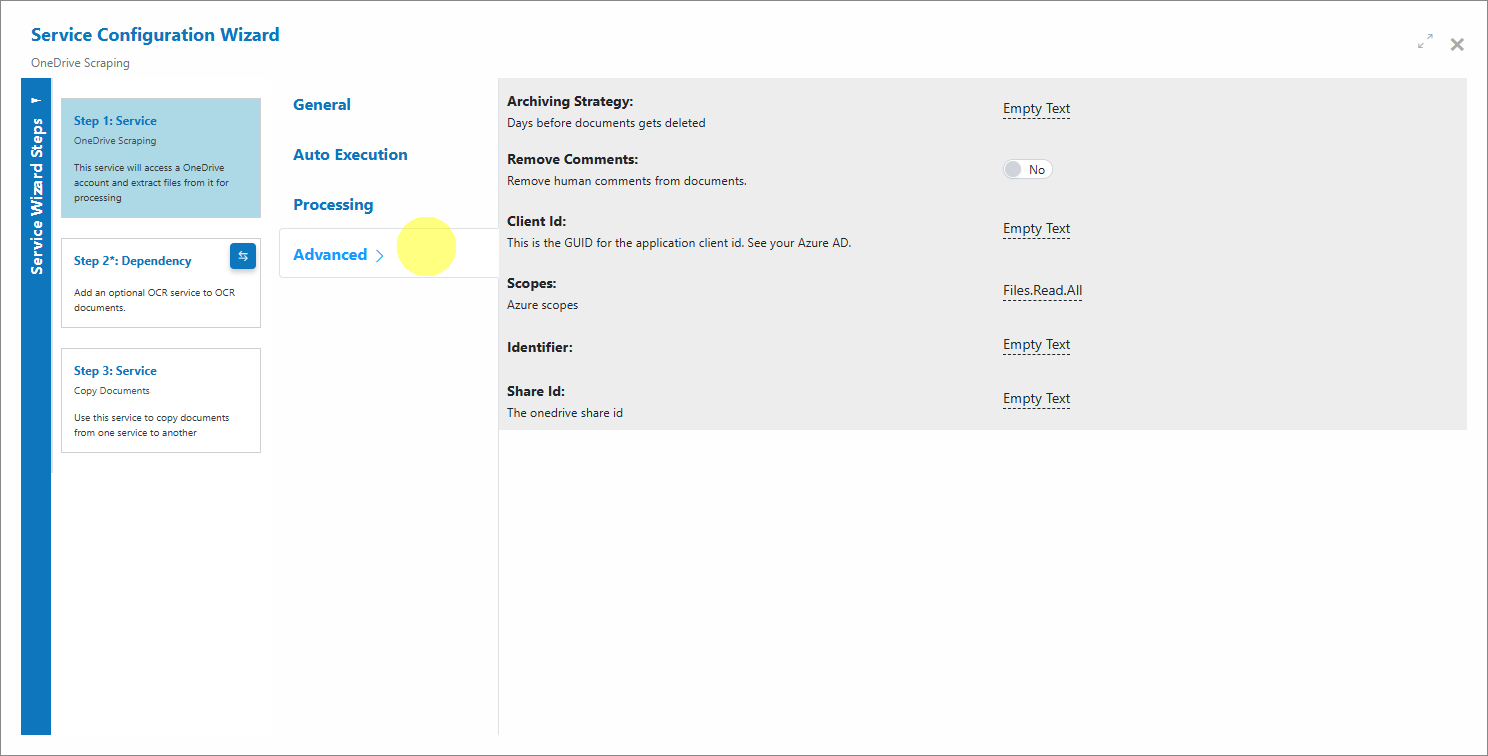
Advanced
Provide Microsoft Graph details (Client Id, Scopes) and target identifiers (e.g., Share Id).
Info
Default settings are sufficient for most use cases. Only fill the Advanced fields that apply to your folder and authentication setup.
Service configuration settings¶
-
General
Enabled: Turn the Service on or off.
Password: Optional. Used for Service authentication if required by your configuration. Can also be set via Custom Code.
URL: Microsoft Graph endpoint. Default: https://graph.microsoft.com/v1.0 -
Auto Execution
Batch Size: Number of items to ingest per scheduled cycle.
Execution Interval: How often the scraper runs (minimum 10 minutes).
Auto Execution: Enable to run on schedule. -
Processing
Document Processed Status: The status applied after a file is successfully ingested by the scraper. Force PDF Image: If enabled, all PDF objects/layers/widgets are removed and page images are used (useful for consistent OCR). -
Advanced
Archiving Strategy: Days before documents get deleted (lifecycle management).
Remove Comments: Remove human comments from documents before downstream processing.
Client Id: GUID for your Azure app registration’s Client ID (required for Microsoft Graph access).
Scopes: Azure permission scopes for Graph. Example: Files.Read.All.
Identifier: Optional context identifier (e.g., user or drive context) if required by your setup.
Share Id: The OneDrive share ID of the target folder to monitor.
Info
AIForged handles token acquisition for Microsoft Graph using a secure, modern auth flow—no passwords are stored. Provide the Client Id and required scopes; if your organization’s security requires it, you can also use Custom Code to inject additional parameters.
Add and process documents¶
To begin ingesting files with the OneDrive Scraper:
-
Connect the target folder
In Advanced settings, provide the Microsoft Graph details (Client Id, Scopes) and the target folder via Share Id. -
Enable Auto Execution
Set your schedule and Batch Size in Auto Execution. The Scraper will run at the configured interval and import new/updated files. -
Run a first pass (optional)
Trigger a manual run to validate the configuration if your environment supports a “Run Now” action.
When you open the OneDrive Scraper, you’ll see documents queued or processed in the Inbox.
Tip
Start with a small Batch Size until you confirm everything is flowing correctly, then increase gradually to match your volume.
Info
Documents older than 7 days will not be auto-processed.
View imported documents¶
- Open the OneDrive Scraper grid to see newly ingested files.
- Open an item to review its metadata and confirm downstream Services are picking it up as expected.
- After downstream processing, use the usage filter to select Outbox to review processed results.

Known limitations¶
-
Microsoft Graph throttling
Graph enforces rate limits. High-volume folders or very frequent polling may result in 429 responses and back-off delays. -
Permissions and scopes
Your Azure app must have appropriate Graph permissions (e.g., Files.Read.All). Insufficient permissions will block access to the folder. -
Shared links and Share Id
The Share Id must point to the correct OneDrive folder. If the sharing link changes or is revoked, ingestion will fail. -
File locks and in-flight uploads
Files still uploading/syncing in OneDrive may be temporarily inaccessible. The scraper ingests them on subsequent runs once fully available. -
Large files and complex PDFs
Very large PDFs or image-heavy documents can increase downstream processing time. Consider splitting large PDFs for responsiveness. -
Password-protected PDFs
Downstream Services cannot process protected PDFs unless a password is provided.
Tip
Use the AIForged Custom Code utility as a pre-processor to set the password per document, so that AIForged can unlock documents before processing.
Tip
For very large PDFs or TIFFs, consider chunking by page range to avoid hitting size or time limits and to keep processing responsive. Use the AIForged Document Splitter for this task.
Troubleshooting¶
-
Not seeing any files?
- Verify the Share Id points to the correct folder and that the folder contains files.
- Confirm your Azure app has the required Graph scopes (e.g., Files.Read.All) and that the Client Id is correct.
- Check that Auto Execution is enabled and the schedule is active.
-
Authentication or permission errors
- Ensure the Azure app registration is valid and consented per your tenant’s policy.
- If using tenant- or user-specific restrictions, confirm the account/context has access to the target folder.
-
Throttling or intermittent failures
- Reduce polling frequency or Batch Size.
- Stagger ingestion windows to avoid peak hours.
-
Files ingested but downstream processing fails
- Review the downstream Service configuration (OCR, Document Intelligence, rules).
- For password-protected PDFs, provide the password via Custom Code pre-processing.
Best practices¶
- Use a dedicated folder (or subfolders per team/supplier) to keep ingestion clean and predictable.
- Keep Batch Size conservative initially; scale up once you confirm performance and provider throttling behavior.
- Standardize naming conventions (e.g., supplier and date) to simplify downstream routing and search.
- For scans, target 300 DPI and good contrast; consider forcing PDFs to image-only when OCR consistency matters.
- For very large PDFs, split into smaller parts with the Document Splitter to improve throughput and user experience.
Quick start¶
Get results in minutes:
-
Add the Service
- Open your agent, click Add Service, and select OneDrive Scraper.
-
Set Microsoft Graph details
- In Advanced: paste your Client Id, confirm Scopes (e.g., Files.Read.All), and provide the Share Id for the target folder.
-
Enable Auto Execution
- Set the schedule and Batch Size.
-
Validate
- Run a first pass (optional) and confirm new files appear in the scraper grid and flow to downstream Services.
Info
Begin with a small test set in the OneDrive folder to validate end-to-end flow before rolling out to larger teams or suppliers.
FAQ¶
-
Do I need to store passwords or keys?
No. AIForged uses a secure auth flow for Microsoft Graph and manages tokens on your behalf. Provide the required Graph details (e.g., Client Id), and AIForged handles the rest. -
How do I point the scraper to a specific folder?
Provide the folder’s OneDrive Share Id in Advanced settings. Ensure the sharing link remains valid. -
What permissions are required in Azure?
The app typically needs Graph scopes like Files.Read.All to read files. Your security team may require additional admin consent depending on tenant policy. -
How do I deal with very large PDFs?
Use the AIForged Document Splitter to split by page range and keep processing responsive. -
What about password-protected PDFs?
Use Custom Code to provide the password per document so AIForged can unlock files before processing.