⏩ Understanding Document Flows¶
Overview¶
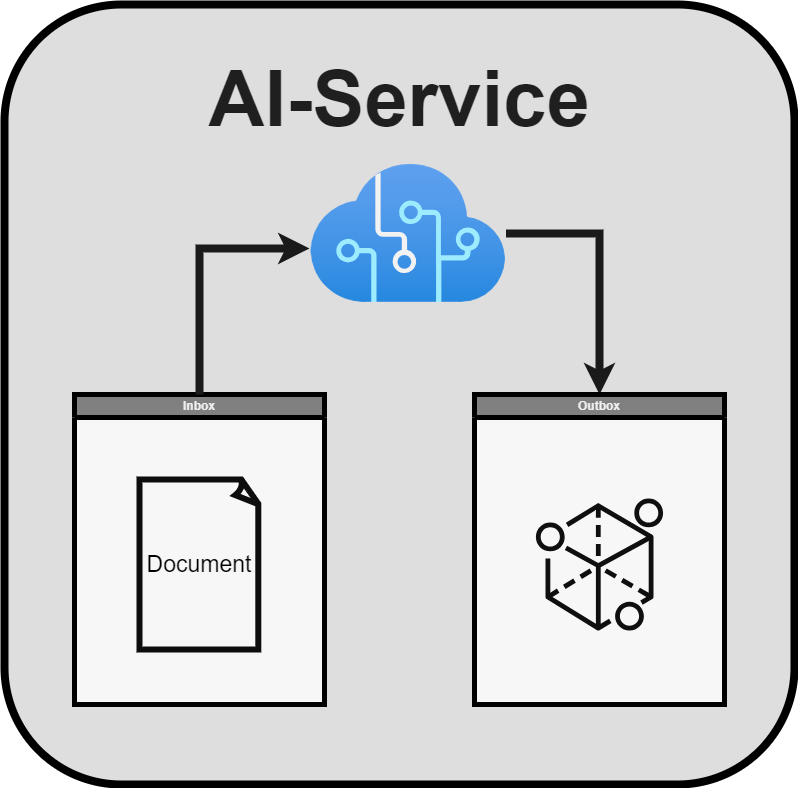
In AIForged, every Service operates a consistent document flow: items arrive in Inbox, move through Processing, may enter Verification (HITL optional), and complete in Outbox. Beyond a single Service, documents form a hierarchy across Services using a Master ID → Id lineage, letting you trace each document’s end-to-end journey.
Tip
If you’re new to the concept of documents in AIForged, start with the Documents overview, then return here to understand how items travel within and across Services.
Document flow in a Service¶
Each Service has an Inbox and an Outbox. A document is ingested into the Inbox, the Service processes it, and one or more result documents are produced in the Outbox.
- Typical stages within a Service
- Inbox
- Intake via upload, scrapers (Email/OneDrive), or API/SDK
- Status examples: None, Received
- Processing
- Utilities (pre/post), OCR, classification, extraction, enrichment
- Status examples: Queued, Processing
- Verification (optional)
- Automatic checks and/or Human-in-the-Loop (HITL) when confidence or policy requires
- Status examples: Verification, CustomVerification
- Outbox
- Finalized results ready for export, webhooks, or downstream integrations
- Status examples: Processed, Verification, Error
- Inbox
Info
- Different Services can produce different outputs. For example:
- Classifiers may produce category/group assignments and routed outputs.
- Extract & Verify Services produce structured fields (parameters), tables, and result artifacts (JSON, PDFs).
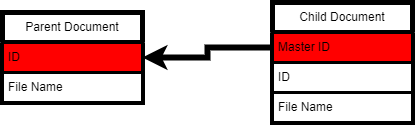
Hierarchical flow (lineage across Services)¶
Documents are connected hierarchically across Services using a Master ID → Id mapping. When an Outbox document from one Service is passed to the next Service’s Inbox, the new document receives a unique Id, and its Master ID points to its source, preserving lineage.
-
Why lineage matters
- End-to-end traceability across multi-step pipelines (e.g., OCR → Classify → Extract & Verify → Export)
- Auditing and troubleshooting across Services and time
- Grouping related items (e.g., email + attachments, or derivatives) under a shared Master ID
-
What persists across hops
- Identity and lifecycle attributes (Id, Master ID, Usage, Status, Category)
- Extracted Parameters and Verifications (where applicable)
- DocumentData artifacts (e.g., Image, Result, Page), so the right bytes are accessible later
Tip
Use Master ID to find all related documents across Services. Use External ID to link documents to records in ERP/CRM/GRC systems for downstream reconciliation.
Cross-Service flows (common patterns)¶
-
OCR → Classifier → Extract & Verify → Export
- Normalize and digitize
- Assign the document to the correct category/type
- Extract structured fields and tables; verify automatically and/or via HITL
- Deliver outputs to downstream systems
-
Classifier → Branch by Category → Specialized Extractors
- Route invoices, receipts, and statements to the best-fit extraction Service or model
- Apply policy-driven verification per category
-
Pre-processors → Main extraction → Post-processors
- Utilities such as Digitizer, PDF Converter, or Image Splitter improve accuracy and speed
- Post-processors enrich, format, or export results
Info
A Service’s Outbox item can be used as the next Service’s Inbox item. This can be done manually, via Auto Execution, or programmatically (API/SDK/RPA) as part of your orchestrated flow.
Status, Usage, and flow control¶
- Usage
- Inbox, Outbox (operational)
- Training, Dataset, Definition (system/learning)
- Status (examples)
- None, Received, Queued, Processing, Verification, Processed, Error
- What drives transitions
- Manual actions (Process, Verify)
- Auto Execution (polling and batch size in Service settings)
- Policy and confidence thresholds (route to HITL or auto-complete)
Tip
Start with small test batches. Use Processing Parameters (Force Re-Processing, Delete Output of Previous Processing, Reset Previous Results) to keep comparisons clean.
Working with flows in Studio¶
- Navigate and filter
- Use Usage and Status filters to focus on a stage (Inbox, Outbox)
- Filter by Category to isolate specific document types
- Process
- Select one or more documents in Inbox → Process
- Tune Processing Parameters for a clean re-run when needed
- Verify (HITL)
- Open items awaiting review, correct fields, and complete
- Review and export
- Open Outbox items to inspect Parameters and DocumentData
- Export or trigger webhooks/integrations to downstream systems
Info
Documents available for labelling and training must first be analyzed (e.g., in a Document Intelligence workflow). Correct Category selection during Analysis improves both classification and extraction quality.
Best practices¶
- Normalize early
- Convert scans to PDF and digitize; split/merge pages to match your target extraction pattern
- Keep Categories clean
- Use Categories for business document types; use Usage/Status for lifecycle
- Use lineage consistently
- Master ID for grouping related items; External ID for system-of-record mapping
- Enforce verification policies
- Route low-confidence or sensitive fields to HITL; record outcomes via Verifications
- Manage outputs deliberately
- Reprocess with cleanup parameters to avoid stale result confusion
Troubleshooting flow issues¶
- Items aren’t moving out of Inbox
- Ensure the Service is enabled; run Process (or enable Auto Execution)
- Auto Execution is not picking up items
- Confirm documents are in Received state, not older than 7 days; check interval and batch size
- Results didn’t change after a re-run
- Enable Force Re-Processing and consider deleting previous outputs
- I lost track of related items across Services
- Search by Master ID; ensure External ID is populated for downstream correlation
Related links¶
- Documents overview: Click Here
- Working in the Service view: Click Here
- Processing documents: Click Here
- Processing Parameters: Click Here
- Document Categories: Click Here
- Document Attributes: Click Here